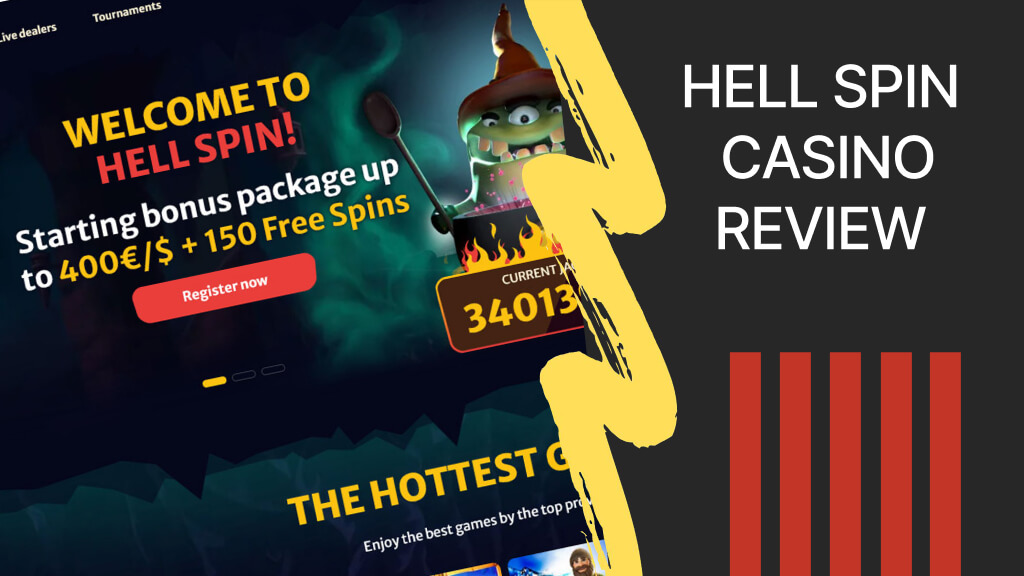
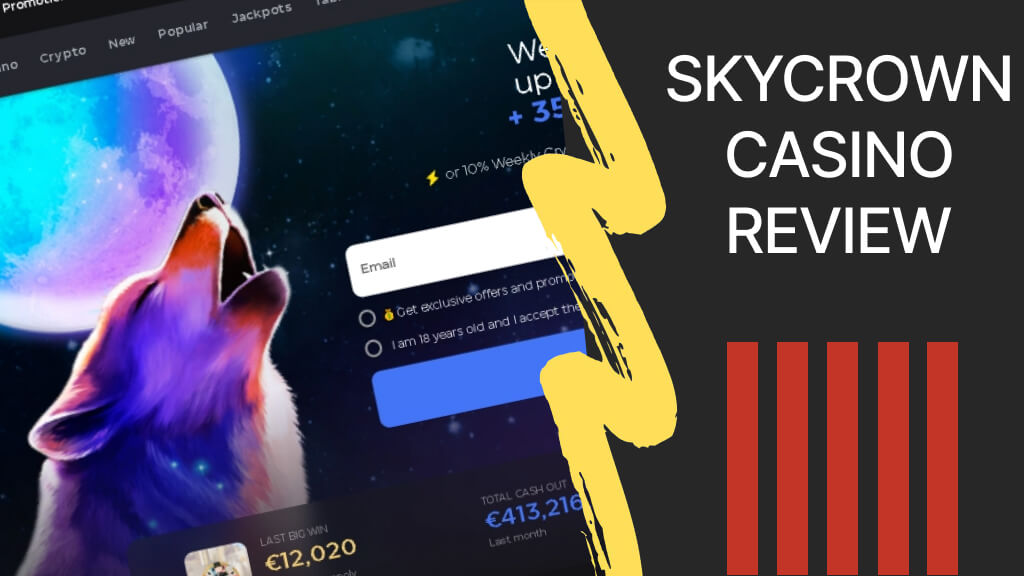
Exciting Aussie Play Casino site in Australia

The company is thoroughly prepared for release and offers all players, and in particular players from Australia unforgettable content and a platform not only for entertainment but also to make money on favorite pokies. Since 2019, perhaps, this brilliant in every sense Aussie Play site with games, has won more than one gaming heart. The…